
GitHub - 42webserv/42webserv
Contribute to 42webserv/42webserv development by creating an account on GitHub.
github.com
개요
먼저 우리가 만든 wev server의 요구 사항을 정리해보자. 구현한 디테일한 기능과 에러처리도 있지만 큰 기능을 위주로 설명을 하려고 한다.
- Kqueue 를 이용한 비동기, 논블로킹 소켓 프로그래밍
- HTTP1.1 프로토콜을 이용한 통신
- CGI를 이용한 동적 웹 사이트 제공
- config file을 이용한 웹서버 설정
간단하게 다시 정리해서 말하자면 nginx를 직접 만들어보는 프로젝트이다.
구조 설계 및 동작 순서
구조를 다이어그램으로 간단히 표현을 한다면 아래 그림과 같다.
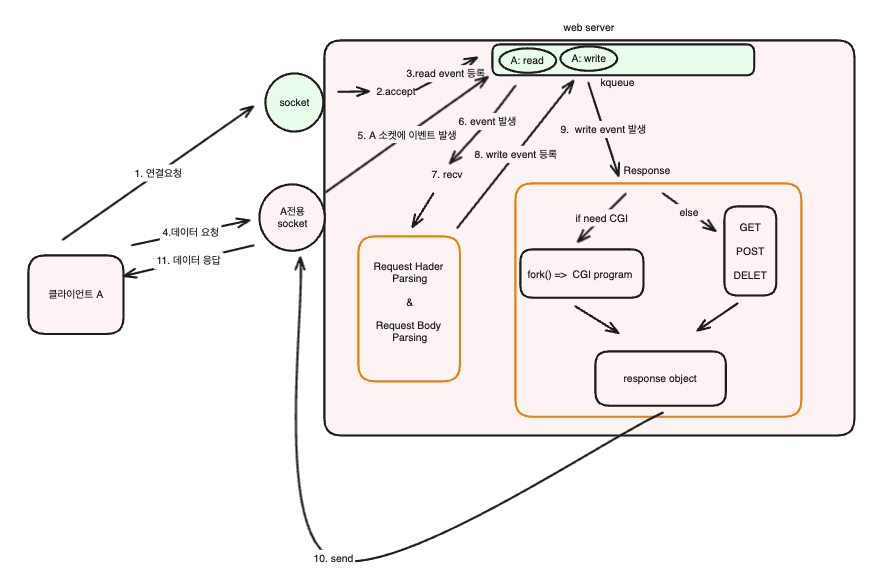
위 그림은 클라이언트 A가 서버에게 데이터 요청을 하는 과정을 순서별로 나타낸 그림이다.
1, 2, 3
- 먼저 처음에 클라이언트 A가 서버에서 연결 요청을 한다. 그러면 연결 요청이 서버의 소켓(새로운 소켓 연결용)으로 들어오게 되고 서버는 accept를 하고 A전용 소켓을 만들어준다. 그리고 kqueue에 A의 Read 이벤트를 등록하게 된다. 그래서 A가 데이터 요청을 하게 되면 Read이벤트가 발생하고 서버는 A가 데이터 요청을 한 것을 알 수 있다.
4, 5, 6, 7, 8
- 클라이언트 A가 데이터 요청을 A 전용 소켓으로 보낸다. 그러면 kqueue에서 A Read이벤트가 발생하고 보낸 데이터를 recv하여 읽는다. 그리고 Request 데이터(HTTP 프로토콜)의 Header와 Body를 파싱한다. 그리고 A Write 이벤트를 kqueue에 등록시켜서 요청에 대한 응답 로직이 돌아갈 수 있도록 해준다.
9, 10
이후 A Write가 발생하고 정적 요청인지 동적요청인지에 따라서 CGI를 생성한다. 동적인 요청이라면 fork를 이용해서 CGI 프로세스를 생성해서 동적 요청을 처리하여 response를 생성하고 정적인 경우는 메서드에 따라서 데이터 응답을 해준다.
그리고 Response Object가 완성된다면 send를 이용해서 A소켓에 데이터를 쓰고 클라이언트는 데이터 응답을 받을 수 있다.
세부 디테일이 매우 많지만 크게 보면 이런 식으로 동작한다.
소켓 프로그래밍
void Worker::run()
{
struct kevent eventList[10];
struct kevent event;
int nevents;
memset(eventList, 0, sizeof(eventList));
memset(&event, 0, sizeof(event));
while (true)
{
nevents = kevent(kq, &events[0], events.size(), eventList, sizeof(eventList) / sizeof(eventList[0]), NULL);
if (nevents == -1)
{
std::cerr << "Error waiting for events: " << strerror(errno) << std::endl;
break;
}
events.clear();
for (int i = 0; i < nevents; i++)
{
event = eventList[i];
uintptr_t &fd = event.ident;
Socket *socket = this->server.findSocket(fd);
if (event.flags & EV_ERROR)
eventEVError(*socket, event);
else if (event.flags & EV_EOF)
eventEOF(*socket, event);
else
{
if (event.filter == EVFILT_READ)
eventFilterRead(*socket, event);
else if (event.filter == EVFILT_WRITE)
eventFilterWrite(*socket, event);
else if (event.filter == EVFILT_TIMER)
eventFilterTimer(*socket, event);
else if (event.filter == EVFILT_SIGNAL)
eventFilterSignal(event);
}
}
}
}
위 코드는 Worker process의 기능을 하는 함수를 가져온 것이다. while 문을 돌려면서 server로 들어오는 요청과 응답을 처리하는 함수이다.
kqueue를 이용해서 이벤트를 처리를 하는 구조이다. 그래서 kevent로 이벤트가 발생한 소켓의 정보를 찾아서 그 이벤트의 종류가 ERROR, EOF, READ, WRITE, TIMER, SIGNAL 이냐에 따라서 따로 처리를 하는 것이다.
kevent는 새로운 이벤트도 등록을 할 수 있고 이벤트가 발생한 소켓의 정보도 알 수 있다. events에는 새로 등록하고 싶은 이벤트는 넣어놓으면 되고 eventList에는 kqueue에서 발생한 이벤트 목록이 저장이 된다.
ERROR
예상치 못한 에러가 난 경우 발생한다. 클라이언트와의 연결을 끊고 관련 메모리를 정리한다.
EOF
클라이언트쪽에서 먼저 연결을 끊은 경우 발생한다. 서버도 같이 연결을 끊고 관련 메모리를 정리한다.
READ
서버로 연결 요청을 한 새로운 클라이언트가 있거나 연결된 클라이언트가 새로운 데이터를 보내온 경우 발생한다.
WRITE
클라이언트에게 응답을 보낼 때 발생하는 이벤트이다.
TIMER
만약 클라이언트와의 연결 시간이 있는 경우, 연결 시간이 끝나면 발생해서 클라이언트와의 연결을 끊는다.
SIGNAL
강제 종료 또는 정상 종료같은 시그널을 kqueue가 모니터링을 하고 있어서 발생시킨다.
Config File
http {
include ./assets/conf/mime.types;
server {
listen 442;
server_name localhost example.com;
root ./assets/html;
client_max_body_size 1;
limit_except GET PUT POST DELETE;
error_page 400 400 400 /404.html;
error_page 404 /404.html;
# for tester
location / {
root ./assets/html;
index index.html;
limit_except GET;
}
location /put_test {
root ./assets/test;
index put_test.txt;
limit_except PUT;
}
...
}
}
위 config file은 nginx의 config file의 규칙을 따르도록 했다. 먼저 config file을 파싱하는 것부터 해야하는데
struct Directive
{
std::string name;
std::string value;
std::string pre_name;
std::vector<Directive> block;
};
나는 이 구조체를 이용해서 config file을 파싱했다. name에는 http, location등 directive 종류를 작성했고 value에는 directive의 값을, pre_name에는 부모의 directive 이름을 작성했다. pre_name은 config file의 유효성 검토를 위해서 추가하였다. 그리고 block은 자식 directive들을 넣었다.
그리고 파싱을 할 때는 자식들을 다 넣어줘야하기 때문에 DFS 알고리즘을 사용해야한다.
그리고 directive의 각 기능은
Creating NGINX Plus and NGINX Configuration Files | NGINX Documentation
Creating NGINX Plus and NGINX Configuration Files Understand the basic elements in an NGINX or NGINX Plus configuration file, including directives and contexts. NGINX and NGINX Plus are similar to other services in that they use a text‑based configurati
docs.nginx.com
nginx의 공식 홈페이지를 통해서 공부하자. 기본적인 것을 몇개 말하자면 listen은 서버의 포트번호를 말하는 것이고 location은 데이터 요청 path에 따라서 허용 메서드나 데이터를 정할 수 있다.
HTTP 프로토콜
HTTP 프로토콜을 기본으로 데이터 통신이 가능하도록 서버를 만들었다. HTTP중에서도 HTTP/1.1 버전을 적용해야한다.
HTTP는 기본적으로 TCP를 이용해서 연결을 하고 HTTP/1.1의 특징은 파이프라이닝과 지속적인 연결(Keep alive)등이 있다.
위 동영상을 보면 많은 도움이 될 것이다.
나는 HTTP/1.1 중에서도 파이프라이닝과 Keep Alive에 대해서 이야기 해보려고 한다.
파이프라이닝을 이야기하기 전에 Keep Alive를 알아야한다. Kepp Alive는 TCP 연결을 계속 유지하는 것을 말한다. 원래 HTTP/1.1 이전에는 한 요청에 한번의 TCP 연결이 필요한다. 이렇게 되면 3 hand shake를 요청을 보낼 때마다 보내야하기 때문에 데이터를 얻는데 너무 오래 시간이 걸리고 비효율적이었다. 하지만 Keep Alive를 사용하면 첫 TCP 연결로 여러 개의 요청을 할 수 있게 되는 것이다.
일단 파이프라이닝은 한 클라이언트가 연속적으로 요청을 보낼 수 있게 해주는 것이다. Keep Alive를 먼저 이야기한 것은 연속 요청을 하기 위해서는 Keep Alive가 기본으로 깔려있어야 가능하기 때문이다.
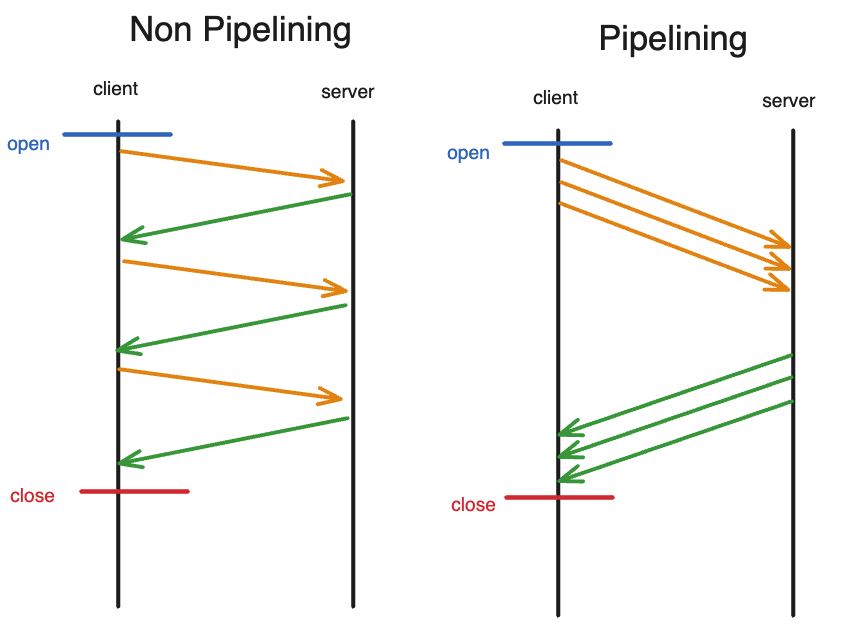
위 그림을 보면 파이프라이닝이 아닐 경우에는 요청의 응답이 올 때까지는 다른 요청을 보낼 수 없었다. 하지만 파이프라이닝같은 경우에는 요청 3개를 한번에 보내고 3개를 한번에 받을 수 있다.
kqueue를 사용한 코드에서는 단일 스레드로 파이프라이닝을 구현할 수 있다. kqueue는 이벤트 기반의 I/O 다중화 메커니즘으로서, 하나의 스레드가 여러 파일 디스크립터에서 발생하는 이벤트를 동시에 처리할 수 있게 해준다.
근데 파이프라이닝을 구현하기 위해서는 여러 디테일한 과정을 추가해야한다.
1. Read, Write 이벤트를 구분해야한다.
위에서 소켓 프로그래밍에 대해서 이야기를 했는데 ERROR, EOF, READ, WRITE, TIMER, SIGNAL 이벤트를 구분해서 감시한다고 했다. 여기서 Read, Write 이벤트를 구분했는데, 이 이유는 Read를 다하고 바고 Write이벤트를 등록 안하고 response처리를 한다면 non-pipelining과 다를게 없어지기 때문이다. 그래서 write와 read를 로직을 분리하기 위해서 이벤트를 따로 등록한 것이다.
2. 요청마다 새로운 버퍼를 생성해줘야한다.
첫 요청의 응답이 끝나기 전에 다음 요청이 들어온 경우 소켓에 대한 버퍼가 하나라면 두번째 요청의 데이터를 저장할 공간이 없어진다. 따라서 요청마다 버퍼를 새로 만들어서 저장을 해줘야한다.
위같은 조건을 지키게 된다면 파이프라이닝을 구현할 수 있다.
'42seoul' 카테고리의 다른 글
| [42Seoul] 식사하는 철학자들 (1) | 2024.02.01 |
|---|---|
| [42Seoul]멤버가 되고 나서 하는 miniShell(미니쉘) 회고 (0) | 2024.01.30 |
| [42Seoul] ft_transcendence 퐁 게임 프로젝트 회고 (1) | 2023.12.17 |
| [42Seoul] Net_practice 문제풀이 (0) | 2023.07.13 |
| [42Seoul] pipex (0) | 2023.07.02 |
GitHub - 42webserv/42webserv
Contribute to 42webserv/42webserv development by creating an account on GitHub.
github.com
개요
먼저 우리가 만든 wev server의 요구 사항을 정리해보자. 구현한 디테일한 기능과 에러처리도 있지만 큰 기능을 위주로 설명을 하려고 한다.
- Kqueue 를 이용한 비동기, 논블로킹 소켓 프로그래밍
- HTTP1.1 프로토콜을 이용한 통신
- CGI를 이용한 동적 웹 사이트 제공
- config file을 이용한 웹서버 설정
간단하게 다시 정리해서 말하자면 nginx를 직접 만들어보는 프로젝트이다.
구조 설계 및 동작 순서
구조를 다이어그램으로 간단히 표현을 한다면 아래 그림과 같다.
위 그림은 클라이언트 A가 서버에게 데이터 요청을 하는 과정을 순서별로 나타낸 그림이다.
1, 2, 3
- 먼저 처음에 클라이언트 A가 서버에서 연결 요청을 한다. 그러면 연결 요청이 서버의 소켓(새로운 소켓 연결용)으로 들어오게 되고 서버는 accept를 하고 A전용 소켓을 만들어준다. 그리고 kqueue에 A의 Read 이벤트를 등록하게 된다. 그래서 A가 데이터 요청을 하게 되면 Read이벤트가 발생하고 서버는 A가 데이터 요청을 한 것을 알 수 있다.
4, 5, 6, 7, 8
- 클라이언트 A가 데이터 요청을 A 전용 소켓으로 보낸다. 그러면 kqueue에서 A Read이벤트가 발생하고 보낸 데이터를 recv하여 읽는다. 그리고 Request 데이터(HTTP 프로토콜)의 Header와 Body를 파싱한다. 그리고 A Write 이벤트를 kqueue에 등록시켜서 요청에 대한 응답 로직이 돌아갈 수 있도록 해준다.
9, 10
이후 A Write가 발생하고 정적 요청인지 동적요청인지에 따라서 CGI를 생성한다. 동적인 요청이라면 fork를 이용해서 CGI 프로세스를 생성해서 동적 요청을 처리하여 response를 생성하고 정적인 경우는 메서드에 따라서 데이터 응답을 해준다.
그리고 Response Object가 완성된다면 send를 이용해서 A소켓에 데이터를 쓰고 클라이언트는 데이터 응답을 받을 수 있다.
세부 디테일이 매우 많지만 크게 보면 이런 식으로 동작한다.
소켓 프로그래밍
void Worker::run()
{
struct kevent eventList[10];
struct kevent event;
int nevents;
memset(eventList, 0, sizeof(eventList));
memset(&event, 0, sizeof(event));
while (true)
{
nevents = kevent(kq, &events[0], events.size(), eventList, sizeof(eventList) / sizeof(eventList[0]), NULL);
if (nevents == -1)
{
std::cerr << "Error waiting for events: " << strerror(errno) << std::endl;
break;
}
events.clear();
for (int i = 0; i < nevents; i++)
{
event = eventList[i];
uintptr_t &fd = event.ident;
Socket *socket = this->server.findSocket(fd);
if (event.flags & EV_ERROR)
eventEVError(*socket, event);
else if (event.flags & EV_EOF)
eventEOF(*socket, event);
else
{
if (event.filter == EVFILT_READ)
eventFilterRead(*socket, event);
else if (event.filter == EVFILT_WRITE)
eventFilterWrite(*socket, event);
else if (event.filter == EVFILT_TIMER)
eventFilterTimer(*socket, event);
else if (event.filter == EVFILT_SIGNAL)
eventFilterSignal(event);
}
}
}
}
위 코드는 Worker process의 기능을 하는 함수를 가져온 것이다. while 문을 돌려면서 server로 들어오는 요청과 응답을 처리하는 함수이다.
kqueue를 이용해서 이벤트를 처리를 하는 구조이다. 그래서 kevent로 이벤트가 발생한 소켓의 정보를 찾아서 그 이벤트의 종류가 ERROR, EOF, READ, WRITE, TIMER, SIGNAL 이냐에 따라서 따로 처리를 하는 것이다.
kevent는 새로운 이벤트도 등록을 할 수 있고 이벤트가 발생한 소켓의 정보도 알 수 있다. events에는 새로 등록하고 싶은 이벤트는 넣어놓으면 되고 eventList에는 kqueue에서 발생한 이벤트 목록이 저장이 된다.
ERROR
예상치 못한 에러가 난 경우 발생한다. 클라이언트와의 연결을 끊고 관련 메모리를 정리한다.
EOF
클라이언트쪽에서 먼저 연결을 끊은 경우 발생한다. 서버도 같이 연결을 끊고 관련 메모리를 정리한다.
READ
서버로 연결 요청을 한 새로운 클라이언트가 있거나 연결된 클라이언트가 새로운 데이터를 보내온 경우 발생한다.
WRITE
클라이언트에게 응답을 보낼 때 발생하는 이벤트이다.
TIMER
만약 클라이언트와의 연결 시간이 있는 경우, 연결 시간이 끝나면 발생해서 클라이언트와의 연결을 끊는다.
SIGNAL
강제 종료 또는 정상 종료같은 시그널을 kqueue가 모니터링을 하고 있어서 발생시킨다.
Config File
http {
include ./assets/conf/mime.types;
server {
listen 442;
server_name localhost example.com;
root ./assets/html;
client_max_body_size 1;
limit_except GET PUT POST DELETE;
error_page 400 400 400 /404.html;
error_page 404 /404.html;
# for tester
location / {
root ./assets/html;
index index.html;
limit_except GET;
}
location /put_test {
root ./assets/test;
index put_test.txt;
limit_except PUT;
}
...
}
}
위 config file은 nginx의 config file의 규칙을 따르도록 했다. 먼저 config file을 파싱하는 것부터 해야하는데
struct Directive
{
std::string name;
std::string value;
std::string pre_name;
std::vector<Directive> block;
};
나는 이 구조체를 이용해서 config file을 파싱했다. name에는 http, location등 directive 종류를 작성했고 value에는 directive의 값을, pre_name에는 부모의 directive 이름을 작성했다. pre_name은 config file의 유효성 검토를 위해서 추가하였다. 그리고 block은 자식 directive들을 넣었다.
그리고 파싱을 할 때는 자식들을 다 넣어줘야하기 때문에 DFS 알고리즘을 사용해야한다.
그리고 directive의 각 기능은
Creating NGINX Plus and NGINX Configuration Files | NGINX Documentation
Creating NGINX Plus and NGINX Configuration Files Understand the basic elements in an NGINX or NGINX Plus configuration file, including directives and contexts. NGINX and NGINX Plus are similar to other services in that they use a text‑based configurati
docs.nginx.com
nginx의 공식 홈페이지를 통해서 공부하자. 기본적인 것을 몇개 말하자면 listen은 서버의 포트번호를 말하는 것이고 location은 데이터 요청 path에 따라서 허용 메서드나 데이터를 정할 수 있다.
HTTP 프로토콜
HTTP 프로토콜을 기본으로 데이터 통신이 가능하도록 서버를 만들었다. HTTP중에서도 HTTP/1.1 버전을 적용해야한다.
HTTP는 기본적으로 TCP를 이용해서 연결을 하고 HTTP/1.1의 특징은 파이프라이닝과 지속적인 연결(Keep alive)등이 있다.
위 동영상을 보면 많은 도움이 될 것이다.
나는 HTTP/1.1 중에서도 파이프라이닝과 Keep Alive에 대해서 이야기 해보려고 한다.
파이프라이닝을 이야기하기 전에 Keep Alive를 알아야한다. Kepp Alive는 TCP 연결을 계속 유지하는 것을 말한다. 원래 HTTP/1.1 이전에는 한 요청에 한번의 TCP 연결이 필요한다. 이렇게 되면 3 hand shake를 요청을 보낼 때마다 보내야하기 때문에 데이터를 얻는데 너무 오래 시간이 걸리고 비효율적이었다. 하지만 Keep Alive를 사용하면 첫 TCP 연결로 여러 개의 요청을 할 수 있게 되는 것이다.
일단 파이프라이닝은 한 클라이언트가 연속적으로 요청을 보낼 수 있게 해주는 것이다. Keep Alive를 먼저 이야기한 것은 연속 요청을 하기 위해서는 Keep Alive가 기본으로 깔려있어야 가능하기 때문이다.
위 그림을 보면 파이프라이닝이 아닐 경우에는 요청의 응답이 올 때까지는 다른 요청을 보낼 수 없었다. 하지만 파이프라이닝같은 경우에는 요청 3개를 한번에 보내고 3개를 한번에 받을 수 있다.
kqueue를 사용한 코드에서는 단일 스레드로 파이프라이닝을 구현할 수 있다. kqueue는 이벤트 기반의 I/O 다중화 메커니즘으로서, 하나의 스레드가 여러 파일 디스크립터에서 발생하는 이벤트를 동시에 처리할 수 있게 해준다.
근데 파이프라이닝을 구현하기 위해서는 여러 디테일한 과정을 추가해야한다.
1. Read, Write 이벤트를 구분해야한다.
위에서 소켓 프로그래밍에 대해서 이야기를 했는데 ERROR, EOF, READ, WRITE, TIMER, SIGNAL 이벤트를 구분해서 감시한다고 했다. 여기서 Read, Write 이벤트를 구분했는데, 이 이유는 Read를 다하고 바고 Write이벤트를 등록 안하고 response처리를 한다면 non-pipelining과 다를게 없어지기 때문이다. 그래서 write와 read를 로직을 분리하기 위해서 이벤트를 따로 등록한 것이다.
2. 요청마다 새로운 버퍼를 생성해줘야한다.
첫 요청의 응답이 끝나기 전에 다음 요청이 들어온 경우 소켓에 대한 버퍼가 하나라면 두번째 요청의 데이터를 저장할 공간이 없어진다. 따라서 요청마다 버퍼를 새로 만들어서 저장을 해줘야한다.
위같은 조건을 지키게 된다면 파이프라이닝을 구현할 수 있다.
'42seoul' 카테고리의 다른 글
| [42Seoul] 식사하는 철학자들 (1) | 2024.02.01 |
|---|---|
| [42Seoul]멤버가 되고 나서 하는 miniShell(미니쉘) 회고 (0) | 2024.01.30 |
| [42Seoul] ft_transcendence 퐁 게임 프로젝트 회고 (1) | 2023.12.17 |
| [42Seoul] Net_practice 문제풀이 (0) | 2023.07.13 |
| [42Seoul] pipex (0) | 2023.07.02 |